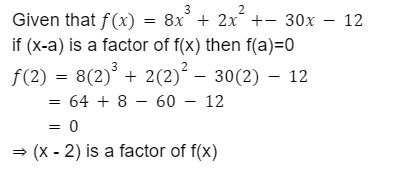The table below has question-wise data on the performance of students in an examination. The marks for each question are also listed. And there is no negative (or) partial marking in the examination
Q.No
Marks
Answered
correctly
Answered
wrongly
Not
Attempted
1
2
3
1
2
3
14
30
24
20
15
26
16
5
0
What is the average of marks obtained by the class in the examination?
1.46
2.92
3
2.86
Correct Answer
Option 2
Solution
Total no. of students = (14 + 20 + 16) = 50
Total marks obtained = (14 × 1) + (30 × 2) + (24 × 3)
= 14 + 60 + 72
= 146
Avg. marks = 146/50 = 2.92
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
f(x) = 8x^3 + 2x^2 - 30x - 12, then which of the following is a factor of f(x)?
(2x - 6)
(x - 1)
(x - 2)
(x^2 + 4)
Correct Answer
Option 3
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
A rectangle becomes a square when its length and breadth are reduced by 12m and 6m respectively. During this process, the rectangle loses 792m2. Then what is the area of the original rectangle in square meters?
864
1600
2392
4692
Correct Answer
Option 3
Solution
Let side of a square = ‘a’ say
Then the length of a rectangle = a + 12
Breadth of a rectangle = a + 6
We know that,
Area of a rectangle = Area of a square + 792
(a + 12) (a + 6) = a^2 + 792
a^2 + 18a + 72 = a^2 + 792
18a + 72 = 792
a = 40
Area of a rectangle = (a + 12) (a + 6)
= (40 + 12) (40 + 6)
= (52) (46)
= 2392
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
In corona pandemic a person in a town is decided to give Rs.600 to each male senior citizen in the town and Rs.700 to each female senior citizen. Altogether there are 450 senior citizens eligible. However only 7/9th of the eligible men and 2/3rd of the eligible women received the amount. How much money did the person give away in total?
Rs 2,10,000
Rs 1,80,000
Rs 2,00,000
Rs 2,50,000
Correct Answer
Option 1
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
For the integers a, b and c, what would be the minimum and maximum values respectively of a+b-c if log|a| + log|b| + log|c| = 0
-1 and 1
-2 and 2
-3 and 3
-1 and 3
Correct Answer
Option 3
Solution
log|a| + log|b| + log|c| = 0; is possible when |a|, |b| and |c| are equal to +1 (or) -1
Maximum value at a=1; b=1; c=-1
⇒ a + b - c
⇒ 1 + 1 - (-1) = 3
Minimum value at a=-1; b=-1; c=1
⇒ a + b - c
⇒ - 1 - 1 - 1 = -3
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Choose the odd one out. In the group there are three words which have the same vowel sound and one which does not or one which has a vowel sound which is not present in the other three. Choose the one that is DIFFERENT.
MOOD / BLOOD / RUDE / FOOD
Mood
Blood
Rude
Food
Correct Answer
Option 2
Solution
In Options a) c) and d) the vowel sound we get is of the vowel o.
Whereas in Option b) the vowel sound we get is of the vowel a.
Therefore Option b) is the odd one out.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Earth is related to Sun in the same way Wheel is related to ________
Hub
Scooter
Tyre
Road
Correct Answer
Option 1
Solution
Here the relationship is the first rotates around the second.
Earth rotates around the Sun, in the same way the wheel rotates round a hub
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Substitute the following sentence with one word.
A state of a person, who is asked to choose between one of the two in vulnerable things
Ebullient
Dilemma
Emetic
Dialectical
Correct Answer
Option 2
Solution
Option a) Ebullient means lively and cheerful
Option b) Dilemma means a state of a person, who is asked to choose between one of the two in vulnerable things
Option c) Emetic means inducing vomiting
Option d) Dialectical means relating to the logical discussion of ideas and opinions
Therefore the right answer is Option b)
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Read the passage below and answer the question
Reviving the practice of using elements of popular music in classical composition, an approach that had been in hibernation in the United States during the 1960s, composer Philip Glass (born 1937) embraced the ethos of popular music in his compositions. Glass based two symphonies on music by rock musicians David Bowie and Brian Eno, but the symphonies' sound is distinctively his. Popular elements do not appear out of place in Glass's classical music, which from its early days has shared certain harmonies and rhythms with rock music. Yet this use of popular elements has not made Glass a composer of popular music. His music is not a version of popular music packaged to attract classical listeners; it is high art for listeners steeped in rock rather than the classics.
The passage addresses which of the following issues related to Glass's use of popular elements in his classical compositions?
How it is regarded by listeners who prefer rock to the classics
How it has affected the commercial success of Glass's music
Whether it has contributed to a revival of interest among other composers in using popular elements in their compositions
Whether it has caused certain of Glass's works to be derivative in quality
Correct Answer
Option 4
Solution
One of the important points that the passage makes is that when Glass uses popular elements in his music, the result is very much his own creation (it is “distinctively his”). In other words, the music is far from being derivative. Thus one issue that the passage addresses is the one referred to in answer Option d) — it answers it in the negative. The passage does not discuss the impact of Glass's use of popular elements on listeners, on the commercial success of his music, on other composers or on Glass's reputation, so none of Options a) through c) is correct.
The correct answer is Option d).
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Find the mirror image of the given word “EXAGGERATED”?
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
If the transparent piece of paper is folded along the middle, which of the following illustrations will result?
Correct Answer
Option 1
Solution
The right side is the mirroring to the left hand side. The line on the two sides will overlap.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Find out from amongst the four alternatives as to how the pattern would appear when the transparent sheet is folded along the dotted line?
Correct Answer
Option 4
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Which of the following regularization techniques is specifically designed to reduce overfitting in linear models by adding a penalty for large coefficients?
Lasso Regression
Ridge Regression
Elastic Net
Principal Component Regression
Correct Answer
Option 2
Solution
Ridge regression adds an L2 regularization penalty to the loss function, which helps to control the magnitude of the coefficients.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What is the primary drawback of using a single-layer perceptron?
It can only handle binary classifications
It cannot learn non-linear decision boundaries
It requires a larger dataset to converge
It is too computationally intensive
Correct Answer
Option 2
Solution
A single-layer perceptron can only model linear decision boundaries, which limits its applicability to linearly separable data
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Given a dataset of 10,000 emails, 100 of which are spam, we use a Naive Bayes Classifier to determine if a new email is spam. If the word "free" appears in 1% of the non-spam emails and in 50% of the spam emails, calculate the probability that an email containing the word "free" is spam. Assume the prior probability of an email being spam is 0.01 (Upto 2 decimals)
0.33
Correct Answer
Option 1
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.00
You are working on a classification problem using logistic regression. The goal is to classify whether a customer will buy a product or not, based on features such as age, income, and browsing history. The logistic regression model estimates the probability that the output variable y=1 given the input X, using the sigmoid function. After training the model, you plot the confusion matrix and find that you have a high false positive rate. Which of the following strategies will most likely reduce the false positive rate without affecting true positives?
Increase the learning rate in gradient descent.
Decrease the threshold for classifying the predicted probabilities
Add interaction terms between features to capture non-linear relationships
Increase the decision threshold from the default 0.5 to a higher value.
Correct Answer
Option 4
Solution
Increasing the threshold will classify fewer samples as positive, which should reduce false positives. Lowering the threshold would have the opposite effect, and increasing the learning rate or adding interaction terms addresses other problems, such as model complexity or convergence, but won't directly lower the false positive rate.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
You are using Support Vector Machines (SVM) with a Gaussian kernel for a classification task. The Gaussian kernel is defined as:
What is the effect of increasing the value of σ\sigmaσ in the Gaussian kernel?
The decision boundary becomes more flexible and prone to overfitting.
The decision boundary becomes smoother and more linear.
The margin between support vectors decreases.
The number of support vectors used in the model increases.
Correct Answer
Option 2
Solution
Increasing σ\sigmaσ in the Gaussian kernel results in a smoother decision boundary, as the kernel becomes less sensitive to small differences between data points. This leads to a more linear decision boundary and reduces overfitting.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
You are applying the K-means algorithm to cluster the following 2D data points: (1,1), (2,2), (3,3), (8,8), (9,9), (10,10). After the first iteration, the centroids of the two clusters are (2,2) and (9,9). Calculate the new centroids after assigning data points to the nearest centroids.
(2,2) and (9,9)
(2,2) and (8.5,8.5)
(2,2) and (9.5,9.5)
(3,3) and (9,9)
Correct Answer
Option 1
Solution
Given the initial centroids, the data points (1,1), (2,2), and (3,3) would belong to the centroid (2,2), and the points (8,8), (9,9), and (10,10) would belong to the centroid (9,9). The new centroids would still be (2,2) and (9,9) because the averages of the points assigned to each cluster are the same as the initial centroids.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
In a dataset of 1000 samples, the model has 800 true positives, 100 false positives, and 100 false negatives. What is the precision of the model?
0.89
0.80
0.75
0.90
Correct Answer
Option 2
Solution
Precision = TP / (TP + FP) = 800 / (800 + 100) = 800 / 900 = 0.888, which rounds to 0.89 (not listed, so B is closest).
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
In a dataset, you apply Lasso regression and the coefficients of the predictors are: [1.5, 0, 0.5, 0]. What is the effective number of predictors used in the model?
2
Correct Answer
Option 1
Solution
Lasso regression can shrink some coefficients to zero. Here, only the first and third coefficients are non-zero, indicating 2 predictors.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Using a confusion matrix, if TP = 50, TN = 30, FP = 10, and FN = 10, what is the specificity of the model? (Upto 2 decimals)
A data normalization method scales a feature’s values between 0 and 1. If the original values of a feature range from 50 to 100, what will the normalized value of 75 be? (Upto one decimal)
If a neural network has 4 input neurons, 3 hidden neurons, and 2 output neurons, how many total weights (consider bias as weights) does this network have?
23
Correct Answer
Option 1
Solution
Weights from input to hidden layer=(Number of inputs+1 bias)×Number of hidden neurons
=(4+1)×3=5×3=15
Weights from hidden to output layer=(Number of hidden neurons+1 bias)×Number of output neurons
=(3+1)×2=4×2=8
Adding the two gives us the total number of weights:
Total weights=15+8=23
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
In a principal component analysis (PCA) problem, the dataset has 3 features: X1,X2,X3. After running PCA, the eigenvalues for the principal components are 5.0,2.0,1.0. What percentage of the total variance is explained by the first two principal components? (Upto one decimal)
87.5
Correct Answer
Option 1
Solution
⅞ *100
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
Which of the following statements are true regarding the softmax function?
a. For each category of the output, the value of the softmax function is between 0 and 1 inclusive.
b. In the softmax function, the sum of probabilities of an observation belonging to each of the classes is 1
c. The input value to the softmax function can be positive, negative, or even zero.
d. The softmax function can be implemented as
for each of the k neurons of the output layer.
Note: np implies numpy.
All the mentioned statements are true.
All the mentioned statements except d are true
All the mentioned statements except c and d are true
All the mentioned statements except b are true
Correct Answer
Option 1
Solution
All the mentioned statements are true.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
w1 = 1, w2 = 1, b = -2
w1 = 1, w2 = 0, b = -2
w1 = 0, w2 = 1, b = -2
w1 = 2, w2 = 1, b = 4
Correct Answer
Option 1
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
While running multiple linear regression, let's say you have reason to believe that several predictors/features are correlated.
Mark the statements which are correct regarding what problems can be raised by those correlated predictors and how can they be handled? [MSQ]
Coefficient estimates and signs will stay the same regardless of predictors included in the model.
No coefficients will have 0 included in confidence intervals.
Many significant predictors can have high p-value indicating they are insignificant.
We can deal with this problem by either removing or combining these correlated predictors.
Correct Answer
Option 3,4
Solution
There will be two primary problems due to correlated predictors,
i. the signs and estimates of the coefficients will vary dramatically.
ii. the resulting p values can be misleading.
For instance, a significant predictor can have a higher p-value indicating its insignificance.
In the first problem, certain coefficients may have confidence intervals that include 0 (meaning it’s difficult to tell whether an increase in the predictor cause an increase in the target variable or not).
This problem can be dealt with by either removing the correlated variables or removing them.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Consider the following statements:
Statement I: RBF kernel can be viewed as an infinite sum over polynomial kernels.
Statement II: As sigma value increases the points are fit to a lower dimension and vice-versa
Only I is correct
Only II is correct
Both I and II are correct
Both I and II are incorrect
Correct Answer
Option 1
Solution
Only I is correct
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Consider the dataset, S given below
Elevation, Road Type and speed Limit are the features and Speed is the target label that we want to predict.
Find the entropy of the dataset, S as given above:
1
Correct Answer
Option 1
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
You are given the task of predicting the price of a house given the various features for a house such as number of rooms, area(sq ft), etc.
How many neurons should you have at the output?
1
Correct Answer
Option 1
Solution
When predicting a single continuous value, like the price of a house, you typically use just one neuron in the output layer of a neural network
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
The "elbow method" is used to determine which of the following in k-means clustering?
The optimal number of clusters
The density of clusters
The initialization of centroids
The distance measure to be used
Correct Answer
Option 1
Solution
The elbow method helps identify the point where increasing the number of clusters does not significantly improve the total within-cluster variance.