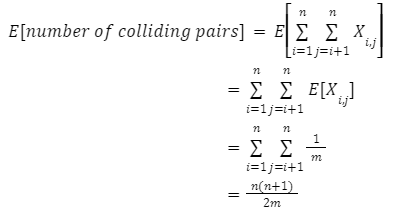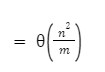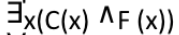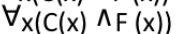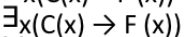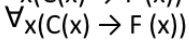Consider a doubly linked list implemented as following:
typedef struct Node
{
int data;
struct Node *f, *b;
};
Where *f, and *b are forward and backward links to the adjacent nodes in the linked list.
Consider a pointer ‘middle’ pointing to a node in the list, which is neither the first nor the last node of the doubly linked list. Which among the following code segments deletes the node pointed by ‘middle’ pointer?
middle -> b -> f = middle -> f ; middle -> f -> b = middle -> b;
middle -> b -> b = middle -> f ; middle -> f -> f = middle -> b;
middle -> f -> b = middle -> f ; middle -> b -> f = middle -> b;
middle -> b -> f = middle -> b ; middle -> f -> b = middle -> f;
Correct Answer
Option 1
Solution
Consider the doubly linked list as above.
middle -> b -> f = middle -> f ; middle -> f -> b = middle -> b;
middle -> b -> f means pointing to 3rd node and it gets assigned by middle -> f means 4th node, hence now f link of 2nd node is pointing to 4th node now.
Similarly the same thing happens from 3 -> 4 links too.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Choose the correct option, from the following:
I) We can find a cycle in the graph using BFS.
II) We can find a cycle in the graph using DFS.
Only I is correct
Only II is correct
Both I and II are correct
None is correct
Correct Answer
Option 2
Solution
Once DFS finds a cycle, the stack will contain the nodes forming the cycle. The same is not true for BFS, so you need to do extra work if you want to also print the found cycle. This makes DFS a lot more convenient.
Consider the following example:
Visiting a node twice in BFS does not necessarily mean a cycle is present in the graph. For example, in the graph,
BFS will proceed as (with source = A):
1) Visit A
2) Visit B,F
3) Visit C, D
4) Visit D, E
As we can see, the D gets visited twice, but there is no cycle in the graph. So, BFS is a bad choice if we wish to find a cycle in a directed graph, but BFS works fine to detect a cycle if our graph is undirected (in which case nearly any graph traversal will work, anyways).
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
The number of different Unlabeled Binary Trees can be there with 4 nodes are ___
14
Correct Answer
Option 1
Solution
The tree below is considered as unlabeled tree with 3 nodes
A program attempts to generate as many permutations as possible of the string, ‘abcd’ by pushing the characters m, n, q, r in the same order onto a stack, but it may pop off the top character at any time. Which one of the following strings CANNOT be generated using this program?
n r q m
m n r q
q r n m
None of the above
Correct Answer
Option 4
Solution
So we have a sequence of elements m, n, q,r on which we can apply push and/pop operations. When we pop, the element at top will be popped off and printed in the sequence and we need to find which sequence among the options doesn’t matches to valid output.
m n q r
a)
b)
c)
All a,b,c options are valid sequences hence none of the above is the correct option.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Height of complete 10-ary tree with 10000 nodes is : ___
4
Correct Answer
Option 1
Solution
A complete k-ary tree is a k-ary tree in which all leaves have the same depth and all internal nodes have degree k. How many leaves does a complete k-ary tree of height h have? The root has k children at depth 1, each of which has k children at depth 2, etc. Thus, the number of leaves at depth h is kh. Consequently, the height of a complete k-ary tree with n leaves is logkn. The number of internal nodes of a complete k-ary tree of height h is
Log 10000 to the base 10 = 4
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Given a tree T. Choose a proper option which describes the tree. [MSQ]
T is BST but not AVL
T is AVL & BST
Inserting ‘g’ into T will violate AVL property
Inserting ‘6’ into T will violate AVL property.
Correct Answer
Option 2,4
Solution
Given tree is a Binary search tree. An AVL tree is a BST where for every node in the tree, the height of left & right subtree differ by at most 1.
When 9 is inserted, the height of the left & right subtree of 8 is 0, which is acceptable. Whereas when 6 is inserted, the height of the left subtree of 8 is 2 & right subtree is 0 & difference = (2 - 0) = 2. This is a violation of AVL property.
Hence only ii & iv are correct.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.00
Consider the following Binary Search Tree
If we randomly search one of the keys present in the above BST, what would be the expected number of comparisons?
2.75
2.25
2.57
3.25
Correct Answer
Option 3
Solution
Expected number of comparisons = (1*1 + 2*2 + 3*3 + 4*1)/7 = 18/7 = 2.57
You count the for every element 𝑋 in the tree the number of comparisons it takes to locate it, say 𝐶(𝑋). Then
𝐸[# of comparisons]=∑𝑋∈{𝐴,…,𝐻}𝑝𝑋⋅𝐶(𝑋),
where 𝑝𝑥 denotes the probability that 𝑋 is chosen, which is the same for all 𝑋, namely 1/8. In other words, you compute the average over the 𝐶(𝑋)s.
for level 1 only one comparison because only 1 node (root) at level 1 => 1*1
then at level 2 we gave 2 nodes hence 2*2...
in this way we will calculate all combinations
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What is the output of the given code segment
a = {'x': 1, 'y': 2}
b = {'z': 3, **a}
print(b)
{'z': 3, 'x': 1, 'y': 2}
{'x': 1, 'y': 2, 'z': 3}
Error
{'z': 1, 'x': 3, 'y': 2}
Correct Answer
Option 1
Solution
The dictionary unpacking (**a) spreads the key-value pairs from a into b. The result is a merged dictionary with the contents of both dictionaries.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What is the output of the given code segment
class GATE:
x = []
t1 = GATE()
t2 = GATE()
t1.x.append(1)
print(t2.x)
[]
[1]
AttributeError
Error
Correct Answer
Option 2
Solution
Class variables like x are shared across all instances of the class. Since t1 and t2 share the same x, appending to t1.x also affects t2.x.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What is the output of the given code segment?
a, b = 5, 10
a, b = (lambda x: (x + 1, x + 2))(a)
print(a, b)
6, 7
5, 10
Error
TypeError
Correct Answer
Option 1
Solution
The lambda function takes a as input and returns a tuple (a+1, a+2), which is unpacked into a and b.
So a = 6 and b = 7.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What is the output of the given code segment?
def func(val, lst=[]):
lst.append(val)
return lst
print(func(10))
print(func(20, []))
print(func(30))
[10], [20], [10, 30]
[10], [20], [30]
[10], [10, 20], [30]
[10, 20], [20], [10, 30]
Correct Answer
Option 1
Solution
func(10) appends 10 to the default list lst.
func(20, []) appends 20 to a new empty list, without modifying the default list.
func(30) appends 30 to the previously modified default list (which already contains 10).
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What is the output of the given code segment?
def func(val, lst=None, counter=0):
if lst is None:
lst = []
def inner(value, cnt):
lst.append(value)
cnt += 1
return lst, cnt
return inner(val, counter)
print(func(10))
print(func(20, [5]))
print(func(30))
print(func(40, counter=3))
([10], 1), ([5, 20], 1), ([30], 1), ([40], 4)
([10], 1), ([5, 20], 1), ([10, 30], 1), ([40], 4)
([10], 1), ([5, 20], 1), ([30], 1), ([40], 6)
([10], 1), ([5, 20], 2), ([10, 30], 1), ([40], 4)
Correct Answer
Option 1
Solution
Step-1: func(10) initializes an empty list because lst=None and calls inner with val=10 and counter=0. lst.append(10) adds 10 to the list, and the counter is incremented to 1. Result: ([10], 1).
Step-2: func(20, [5]) passes a non-empty list [5] and counter=0. inner appends 20 to [5], and counter is incremented to 1. Result: ([5, 20], 1).
Step-3: func(30) uses the default lst=None again, initializing a new empty list and calling inner with val=30 and counter=0. Result: ([30], 1).
Step-4 func(40, counter=3) uses the default lst=None but sets counter=3. A new list is initialized, and 40 is appended. The counter is incremented to 4. Result: ([40], 4).
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Which one of the following values is returned by the function GATE(X) for X = [7, 4, 6, 8, 5]?
GATE(X)
T[1] ← 1
for i ← 2 to length(X)
T[i] ← T[i-1] * 2
if X[i-1] < X[i]
T[i] ← T[i] + 1
end if
end for
return T
[1, 2, 4, 9, 16]
[1, 3, 5, 11, 22]
[1, 2, 4, 8, 16]
[1, 2, 5, 9, 16]
Correct Answer
Option 2
Solution
Initialization: T[1] ← 1.
First iteration: i = 2, X[1] = 7, X[2] = 4.
Since 7 > 4, the condition X[i-1] < X[i] is false. So, T[2] = T[1] * 2 = 1 * 2 = 2.
Second iteration: i = 3, X[2] = 4, X[3] = 6.
Since 4 < 6, the condition is true. So, T[3] = (T[2] * 2) + 1 = (2 * 2) + 1 = 5.
Third iteration: i = 4, X[3] = 6, X[4] = 8.
Since 6 < 8, the condition is true. So, T[4] = (T[3] * 2) + 1 = (5 * 2) + 1 = 11.
Fourth iteration: i = 5, X[4] = 8, X[5] = 5.
Since 8 > 5, the condition is false. So, T[5] = T[4] * 2 = 11 * 2 = 22.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
For the input X = [3, 8, 7, 10], what is the value returned by GATE(X, length(X))?
GATE(X, i)
if i = 1
return 1
else
if X[i] > X[i-1]
return GATE(X, i-1) * 2
else
return GATE(X, i-1) + 1
end if
end if
4
5
6
7
Correct Answer
Option 3
Solution
i = 4: Since X[4] = 10 and X[3] = 7, the condition X[4] > X[3] is true, so GATE(X, 3) * 2.
i = 3: X[3] = 7 and X[2] = 8, the condition X[3] > X[2] is false, so GATE(X, 2) + 1.
i = 2: X[2] = 8 and X[1] = 3, the condition X[2] > X[1] is true, so GATE(X, 1) * 2.
- Initial Call: GATE(child_dict, 0) starts with answer = 2.
- First iteration: For j = 1, it calls GATE(child_dict, 1):
- Second Call: GATE(child_dict, 1) starts with answer = 2.
- For j = 3: Calls GATE(child_dict, 3) which returns 2 (since 3 has no children). So, answer = 2 * 2 = 4.
- For j = 4: Calls GATE(child_dict, 4):
- Third Call: GATE(child_dict, 4) starts with answer = 2.
- For j = 6, GATE(child_dict, 6) returns 2. So, answer = 2 * 2 = 4.
- Result: answer = 4.
- Result: answer = 4 * 4 = 16.
- For j = 2: Calls GATE(child_dict, 2):
- Fourth Call: GATE(child_dict, 2) starts with answer = 2.
- For j = 5, GATE(child_dict, 5) returns 2. So, answer = 2 * 2 = 4.
- Final Result: 2 * 16 * 4 = 128.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
What is the output of this code?
def GATE(child_dict, i):
if i not in child_dict.keys():
return 1
answer = 1
for j in child_dict[i]:
answer += GATE(child_dict, j)
return answer
child_dict = dict()
child_dict[0] = [1, 2]
child_dict[1] = [3, 4]
child_dict[2] = []
child_dict[3] = [5, 6]
print(GATE(child_dict, 0))
6
7
8
5
Correct Answer
Option 2
Solution
- Initial Call: GATE(child_dict, 0) starts with answer = 1.
- First iteration: For j = 1, it calls GATE(child_dict, 1):
- Second Call: GATE(child_dict, 1) starts with answer = 1.
- For j = 3, it calls GATE(child_dict, 3):
- Third Call: GATE(child_dict, 3) starts with answer = 1.
- For j = 5, it calls GATE(child_dict, 5) (returns 1 since 5 has no children).
- For j = 6, it calls GATE(child_dict, 6) (returns 1 since 6 has no children).
- Result: answer = 1 + 1 + 1 = 3.
- For j = 4, it calls GATE(child_dict, 4) (returns 1 since 4 has no children).
- Result: answer = 1 + 3 + 1 = 5.
- For j = 2: Calls GATE(child_dict, 2) (returns 1 since 2 has no children).
- Final Result: 1 + 5 + 1 = 7.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
A stable sort preserves the order of values that are equal with respect to the comparison function. We have a list of three dimensional points [(1, 2, 8),(2, 1, 7),(6, 5, 1),(5, 6, 2),(0, 2, 2),(9, 1, 9),(4,4,4)]. We sort these in ascending order by the second coordinate. Which of the following corresponds to a stable sort of this input?
Stable sort definition: A sorting algorithm is said to be stable if two objects with equal keys appear in the same order in sorted output as they appear in the input array to be sorted.
Step-1: [(6,5,1),(5, 6, 2),(0, 2, 2),(4,4,4),(2, 1, 7),(1, 2, 8),(9, 1, 9)] it sort according to third coordinate. But in question they are expecting to find us with the help of a second coordinate.
Note: The pairs with equal values on the second coordinate are [(2, 1, 7), (9, 1, 9)and (1, 2, 8),(0, 2, 2)]. These should appear in the same order in the output.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Given elements, Find the height of the optimal merge pattern?
17, 28, 13, 7, 8, 12, 10, 4
[ Hint: Height starts with 0 ]
4
Correct Answer
Option 1
Solution
Height of the tree is 4 and the root started with 0.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.00
Which of the following represents a binary max-heap?
25, 12, 16, 13, 10, 12, 4
25, 12, 13, 16, 4, 10, 12
25, 10, 13, 16, 4, 10, 12
25, 14, 16, 13, 10, 4, 12
Correct Answer
Option 4
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
While forming the Minimum Spanning Tree(MST) of the following graph using Prim's Algorithm, in what order will the edges be added?(Start from Vertex A)
A-C, C-E, E-F, C-G, G-B, B-D, E-H
A-B, A-E, E-F, C-G, G-B, B-D, E-H
A-E, A-B, E-F, C-G, G-B, B-D, E-H
A-C, A-B, B-D, C-G, G-B, A-E, E-F
Correct Answer
Option 1
Solution
A-C, C-E, E-F, C-G, G-B, B-D, E-H.
The MST Prim’s algorithm starts from vertex A and will reach
A-C because of minimum weight.
C-E next minimum weight or we can also traverse C-G. Both are correct.
E-F next minimum weight
C-G next minimum weight
G-B next minimum weight
B-D next minimum weight.
E-H next minimum weight
Note: Total 8 vertices and 8-1(n-1) edges.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Given the frequencies and corresponding full binary tree using huffman code algorithm.
Character
A
B
C
D
E
F
Frequency
50
35
15
12
2
3
Find the difference between Y and X is _____?
3
Correct Answer
Option 1
Solution
Difference= 35-32 = 3
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
Which of the following statement(s) is/are FALSE? [MSQ]
Given a connected graph G = (V,E), if a vertex v ∈ V is visited during level k of a breadth-first search from source vertex s ∈ V, then every path from s to v has length at most k.
Any Dynamic Programming algorithm with n subproblems will run in O(n) time.
Depth-first search will take Θ(V2) time on a graph G = (V,E) represented as an adjacency matrix.
Given an adjacency-list representation of a directed graph G = (V,E), it takes O(V ) time to compute the in-degree of every vertex.
Correct Answer
Option 1,2,4
Solution
A: False. The level of a vertex only provides the length of the shortest path from s.
B: False. The subproblems may take longer than constant time to compute, as was the case with the longest increasing subsequence.
C: True. In this case, finding the neighbors of a vertex takes O(V ) time, which makes the total running time(V2).
D: False. The adjacency list structure needs to be traversed to find the incoming edges for each vertex. This structure has a total size Θ(V + E), so this takes(V + E) time to compute.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
Which of the following statement(s) is/are FALSE? [MSQ]
Radix Sort does not work correctly (Means, It does not produce the correct output) if we sort each individual digit using insertion sort instead of counting sort.
Suppose we use a hash function ‘h’ to hash ‘n’ distinct keys into an array ‘’T’ of length ‘m’. Assuming simple uniform hashing, the expected number of colliding pairs of elements is θ(n^2/m)
Let T be a complete binary tree with n nodes. Finding a path from the root of T(T is not necessarily sorted) to a given vertex v ∈ T using breadth-first search takes O(logn) time.
Selection sort and heap sort satisfying stable property.
Correct Answer
Option 1,3,4
Solution
A: False. Insertion sort (as presented in class) is a stable sort, so Radix sort remains correct. The change can worsen running time, though.
B:True.Let Xi,j be an indicator random variable equal to 1 if elements i and j collide, and equal to 0 otherwise. Simple uniform hashing means that the probability of element i hashing to slot k is 1/m. Therefore, the probability that i and j both hash to the same slot Pr(Xi,j)=1/m. Hence,E [Xi,j] = 1/m. We now use linearity of expectation to sum over all possible pairs i and j.
C:False. Breadth-first search requires Ω(n) time. Breadth-first search examines each node in the tree in breadth-first order. The vertex v could well be the last vertex explored.
D:False:
→ Heap-Sort: Heapsort is an in-place algorithm, but it is not a stable sort. The final sequence of the results from heapsort comes from removing items from the created heap in purely size order (based on the key field). Any information about the ordering of the items in the original sequence was lost during the heap creation stage, which came first.
→ Selection Sort: Selection sort algorithm picks the minimum and swaps it with the element at current position.
Example: A={5,2,3,8,4,5,6}
Let's distinguish the two 5's as 5(a) and 5(b) .
After first iteration : 2 will be swapped with the element in 1st position:
A={2,3,4,5(b),5(a),6,8}
Note:Stable with O(n) extra space. Using linked lists .
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
A min heap contains 512 distinct elements with keys ranging from 0 to 511. These keys are stored in an array of 512 indices. To place an element 25 in a min heap, find the maximum difference between maximum level and minimum level is____? [ Hint: Assume root as level 0 ]
8
Correct Answer
Option 1
Solution
Method-1:
The heap is a complete binary tree. The total 512 elements hence there will be 9 levels of the heap. We can get (n/2)th element that can be present at the last level in the worst case. The last level is 9 and level starts from 0.
The heap is not a binary search tree, so we can get the best case as 1st level.
So, The difference= 9-1=8
Method-2:
If you draw a min heap then you will get 512 elements in the worst case position is the last level of the tree.
The best case possibility is level-1 and worst case possibility is level-8.
So, the difference is 9-1=8
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
In a search problem, consider an agent tasked with finding a path in a maze. The agent uses a uninformed search algorithm, which of the following best describes an attribute of this algorithm?
It uses heuristics to guide the search toward the goal efficiently.
It explores all paths blindly without additional knowledge about the environment.
It guarantees the shortest path to the goal if one exists.
It can adapt its strategy based on the response from the environment.
Correct Answer
Option 2
Solution
Uninformed search algorithms, such as breadth-first search or depth-first search, do not utilize heuristics and thus explore the search space blindly. They do not possess additional knowledge about the problem's structure.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
When modeling the conditional independence in a Bayesian network, which of the following statements is true?
If A is independent of B given C, then knowing B provides no additional information about A once C is known.
Conditional independence implies that A and B cannot influence each other regardless of C.
The structure of a Bayesian network cannot represent conditional independence.
If A is dependent on B, it must also be dependent on every variable related to B.
Correct Answer
Option 1
Solution
In a Bayesian framework, A and B being independent given C means that the knowledge of B does not enhance our knowledge about A when C is known.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Which of the following statements about inference in Bayesian networks is true?
Any inference algorithm can calculate marginals without knowledge of the network structure.
Exact inference can always be performed in linear time irrespective of network complexity.
Graphical structures can lead to computational efficiency in performing inferences.
Inference is only possible when all node states are known a priori.
Correct Answer
Option 3
Solution
The graphical structure of Bayesian networks allows for efficient inference by exploiting independence assumptions, which can significantly reduce computational complexity.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
In approximate inference, which of the following statements is true concerning the importance sampling technique?
It guarantees convergence to the true distribution with a finite number of samples.
It assigns weights to samples based on their likelihood, improving estimates.
It assumes that all samples are equally relevant to the inference.
It is primarily used for exact inference rather than approximate inference.
Correct Answer
Option 2
Solution
Importance sampling improves the estimation by weighting samples according to their likelihood in the target distribution, allowing for a more precise approximation.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Which of the following best describes the main advantage of using probabilistic reasoning in AI over deterministic reasoning?
It provides absolute certainty in outcomes.
It allows for reasoning in domains with incomplete or uncertain information.
It simplifies the representation of knowledge.
It requires extensive computation for trivial problems.
Correct Answer
Option 2
Solution
Probabilistic reasoning accommodates uncertainty and incomplete information, enabling models to make more realistic predictions in complex environments, unlike deterministic reasoning, which requires complete certainty.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
∃x p(x) is read as -?
There exists one value in the universe of variable x such that p(x) is true
There exists at least one value in the universe of variable x such that p(x) is false
There exists at least one value in the universe of variable p(x) such that x is true
There exists at least one value in the universe of variable x such that p(x) is true
Correct Answer
Option 4
Solution
There exists at least one value in the universe of variable x such that p(x) is true
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Correct Answer
Option 4
Solution
For every person x, if comedian then x is funny
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
“If my computations are correct and I pay the electric bill, then I will run out of money. If I don’t pay the electric bill, the power will be turned off. Therefore, if I don’t run out of money and the power is still on, then my computations are incorrect.” Convert this argument into logical notations using the variables c, b, r, p for propositions of computations, electric bills, out of money and the power respectively. (Where ¬ means NOT)
if (c Λ b)→r and ¬b→p, then (¬r Λ p)→¬c
if (c ∨ b)→r and ¬b→¬p, then (r Λ p)→c
if (c Λ b)→r and ¬p→b, then (¬r ∨ p)→¬c
if (c ∨ b)→r and ¬b→¬p, then (¬r Λ p)→¬c
Correct Answer
Option 1
Solution
“If my computations are correct and I pay the electric bill, then I will run out of money.\" : if (c Λ b)→r \"If I don’t pay the electric bill, the power will be turned off. Therefore, if I don’t run out of money and the power is still on, then my computations are incorrect.” : (¬r Λ p)→¬c . So, option (A) is correct.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Find the correct topological sequence using indegree elimination method for given graph G=(V,E)
1,6,5,0,3,2,4,7
0,1,3,7,2,4,5,6
1,7,6,5,0,3,2,4
0,5,7,2,3,1,4,6
Correct Answer
Option 1
Solution
Here, we have to take the sequence when indegree becomes ‘0’.
Step-1: identify indegree “0” vertices.
The given graph has two indegree “0” vertices. The vertices are 0 and 1. So, we can start the sequence with either vertex 0 or 1.
Step-2: Remove outgoing edges of vertex 0 or 1. Because of removal of outgoing edges some vertices become indegree “0”.
Step-3: Will continue the process until all vertices indegree 0.
→ The given problem is easy by choosing the eliminating option method.
Option-B: INCORRECT: The last and highest indegree vertex is 7 but we are given a sequence before than his parent vertices.
Option-C: INCORRECT: The last and highest indegree vertex is 7 but we are given a sequence before than his parent vertices.
Option-D: INCORRECT: The last and highest indegree vertex is 7 but we are given a sequence before than his parent vertices.