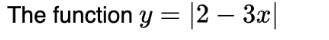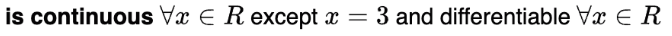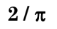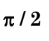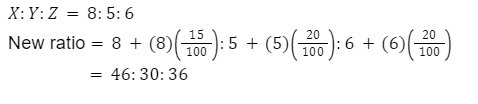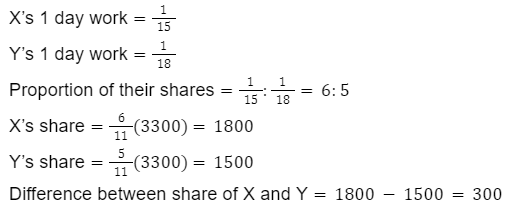The HCF of two numbers is 31 and the other two factors of their LCM are 13 and 16. The larger of the two numbers is
403
322
496
546
Correct Answer
Option 3
Solution
The numbers are 31 x 13 and 31 x 16
∴ Larger number =31 x 16=496
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
6 bells commence tolling together and toll at intervals of 2, 3, 4, 5, 6 and 8 seconds respectively. In 44 minutes how many times do they toll together?
12 times
23 times
22 times
24 times
Correct Answer
Option 2
Solution
LCM of 2, 3, 4, 5, 6 and 8 is 120 (2 minutes)
In 44 minutes, they will toll together =44/2+1=23 times
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
A bag contains three different types of fruits X, Y, Z are in ratio 8:5:6. If the number of fruits in the bag is increased by 15%, 20% and 20% respectively. What is the new ratio of fruits that bag contains?
7:4:3
46:30:36
3:4:5
46:6:36
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
X can fabricate a divider in 15 days while Y alone can assemble it in 18 days, if they construct it together and get an installment of Rs.3300, then what is the difference between the share of X and Y?
400
350
300
600
Correct Answer
Option 3
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
The average salary of all employees in an organization is Rs.7700. The average salary of 9 Technicians is Rs.11000 and the average salary of rest is Rs.5000. How many employees are there in the organization?
25
20
40
28
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Cactus: Succulent :: wood :: ? [MSQ]
Moss
dry
Teak
Hard
Correct Answer
Option 2,4
Solution
Succulent means tender and Juicy. Cactus is a type of succulent plant.
The opposite of succulent is dry and hard, which can be seen in wood.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.00
A person who protects is known as ______?
offender
bystander
defender
mender
Correct Answer
Option 3
Solution
Offender is a person who commits an illegal act.
Bystander is a person who is present at an event but does not take part.
Defender is a person who protects.
Mender is a person who repairs things.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
The child sat ______ her lap.
towards
upon
beside
in
Correct Answer
Option 2
Solution
“Upon” and “on” are both used as prepositions. Prepositions are used to express the relationship of a noun and a pronoun in the sentence with another word. They can be used interchangeably in many cases.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Read the passage and answer the question
PASSAGE
Asiant - poet who dedicated herself to the worship of Lord Krishna …. Meerabai’s life has been etched in the pages of history for her ardent devotion. To celebrate her life and times, a musical called Meera - The musical that has a tracker of her lesser - known poems, premiered online. Around 180 artists took part in the musical, which has been produced by Art of Living. It is a fundraiser for the free education project of the organization.
A life so vibrant and mystic, there have been various versions to her story. Bharathy Harish, coordinator of Madhurya Creation who has also done the screenplay for the musical, says they had to research the life of Meerabai in depth. “We spoke to a traditional folk storyteller in Mewar, through whom we even felt the deep connection that people had for Meerabai.
Several known names, including B Prasana, Sachin Limaye, Chitra Roy, Srinivas Shalini and Gautam Dabir, have arranged music for the performance. Renowned artists such as KS Chitra and Gayatri have given vocals for them. Considering Meerabai a true feminist, the team tried to show the values and strength that Meerabai represented. For instance, Meerabai stopped the practice of animal sacrifice and challenged the custom of ‘Sati’. Despite being a young princess who grew up in a male - dominated social setting,she showed how she could resolve matters’. The team hopes the musical as a learning for viewers. More than 300 people worked for six months on the production.
Another part of the musical was making the show visually appealing. Which is why, a lot of emphasis was laid on costumes which were handled by Madhurya Handloom, which works on revival of traditional fabrics.
Question:
Which practice did Meerabai stop in a male - dominated society that she lived in ?
Dance practice
Folk - storytelling
Sati
Animal sacrifice
Correct Answer
Option 4
Solution
‘Meerabai stopped the practice of animal sacrifice and challenged the custom of ‘Sati’. Despite being a young princess who grew up in a male dominated society, she showed how she could resolve matters.’
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What will be unique binary tree whose preorder & inorder sequences are:
4 2 1 3 5 34 23 6 44
1 2 3 4 5 6 23 34 44
Correct Answer
Option 2
Solution
Explanation:
Step 1:
Preorder:
Inorder:
Step 2:
Preorder:
Inorder:
Step 3:
Preorder:
Inorder:
Step 4:
Preorder:
Inorder:
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Hashing reduces the time required to
Insert an element in a data structure
Delete an element from a data structure
Search/Access an element into a data structure
None
Correct Answer
Option 3
Solution
Hashing is an important Data Structure which is designed to use a special function called the Hash function which is used to map a given value with a particular key for faster access of elements. The efficiency of mapping depends on the efficiency of the hash function used.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
In order to find Minimum Spanning tree from undirected connected graph, we should use Prim’s algorithm if graph is dense otherwise Kruskal’s algorithm.____
True
False
None
Correct Answer
Option 1
Solution
Due to the nature of these algorithms, in the case of a graph with moderate number of edges, we should use Kruskal's algorithm. Prim's algorithm runs faster in a graph with many edges as it only compares limited number of edges per loop, where as Kruskal's start by sorting all the edges in the list then going through them again to check if the edge is part of the minimal spanning tree (MST) or not. Hence although both algorithms have similar running time, number of edges in the graph should be the main component when you are deciding between the algorithms. More edges compared to vertices, use Prim's, otherwise, use Kruskal's.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Given the figure below, which one of the following options gives a negative weight cycle? [MSQ]
B-A, A-F, F-D, A-D, A-C, C-B
B-A, A-C, C-B
B-A, A-F, F-D, D-C, C-B
B-A, A-D, D-C, C-B
Correct Answer
Option 2,3
Solution
After adding all edge weights of every given circuit, The option C forms a negative weight cycle.
Which of the following algorithms is the best algorithm design technique used to find all the pairs of shortest distances in a graph?
Divide and Conquer
Greedy Algorithm
Dynamic Programing
Brute force technique
Correct Answer
Option 3
Solution
The Floyd Warshall algorithm is used to find all the pairs of shortest distances in a graph using dynamic programming.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Let G=(V,E) be the directed, weighted graph shown below.
What is the cost of the shortest paths from ‘a’ to all other remaining vertices in the above graph? [ MSQ]
(a-b,50), (a-c,45)(a-d,10)(a-e,10)(a-e-f,28)
(a-e-b,45)(a-d-e-b-c,45)(a-d,10)(a-e,25)(a-f,∞)
(a-d-e-b-45)(a-c,45)(a-d,10)(a-e,25)(a,f,∞)
(a-e-b,45)(a-c,45)(a-d,10)(a-d-e,25)(a,f,∞)
Correct Answer
Option 3,4
Solution
Two possible Shortest paths:
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.00
Consider an empty hash table of size = 6. The elements 16, 25, 28, 37 are to be inserted. Which of the hash functions results in minimum collision, if linear probing technique is used? [ MSQ]
(x+1) mod 6
2x mod 6
x mod 6
(2x+1) mod 6
Correct Answer
Option 1,3
Solution
Given elements : 16, 25, 28, 37
(x+1) mod 6
(16+1) mod 6 = 17 mod 6 → Slot 5 [ No collision ]
(25+1) mod 6 = 26 mod 6 → Slot 2 [ No collision ]
(28+1) mod 6 = 29 mod 6 → Slot 5 [ Collision ]
(37+1) mod 6 = 38 mod 6 → slot 2 [ Collision ]
2x mod 6
2*16 mod 6 → 32 mod 6 → Slot 2 [ No collision ]
2*25 mod 6 → 50 mod 6 → Slot 2 [ Collision ]
2*28 mod 6 → 56 mod 6 → Slot 2 [ Collision ]
2*37 mod 6 → 74 mod 6 → slot 2 [ Collision ]
x mod 6
16 mod 6 → slot 4 [ No collision ]
25 mod 6 → slot 1 [ No collision ]
28 mod 6 → slot 4 [ Collision ]
37 mod 6 → slot 1 [ Collision ]
(2x+1) mod 6
(2*16+1) mod 6 → 33 mod 6 → Slot 2 [ No collision ]
(2*25+1) mod 6 → 51 mod 6 → Slot 2 [ Collision ]
(2*28+1) mod 6 → 57 mod 6 → Slot 2 [ Collision ]
(2*37+1) mod 6 → 75 mod 6 → slot 2 [ Collision ]
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
The numbers 32,56,87,23,65,26,93 are to be inserted into a hash table of size 7. The hash table implementation uses function as (mod 7) and linear probing to resolve collision. After inserting the given numbers into a hash table, if you apply bubble sort on the final content of the table, then after one pass of the bubble sort, how many elements have changed their position_____?
6
Correct Answer
Option 1
Solution
Given elements : 32,56,87,23,65,26,93
x mod 7
32 mod 7 → 4
56 mod 7 → 0
87 mod 7 → 3
23 mod 7 → 2
65 mod 7 → 2 [ collision ]
(65 mod 7)+1 → 3 [ collision ]
(65 mod 7)+2 → 4 [ collision ]
(65 mod 7)+3 → 5 [ No collision ]
26 mod 7 → 5 [ collision ]
(26 mod 7)+1 → 6 [ No collision ]
The final content is given below table and index starts from 0.
Except 56 elements every element has changed their order.
So, the final answer is 6.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
If D_1,D_2,…D_n are domains in a relation model, then the relation is a table, which is a subset of
D_1⨁D_2⨁…⨁D_n
D_1×D_2×…×D_n
D_1∪D_2∪…∪D_n
D_1∩D_2∩…∩D_n
Correct Answer
Option 2
Solution
If D_1,D_2,…,D_n are domains in a relation model, then the relation is a table, which is a subset of D_1×D_2×…×D_n.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Consider the following ER diagram:
The minimum number of tables required to represent the ER diagram into the relational model is
2
3
4
5
Correct Answer
Option 1
Solution
Minimum no. of tables needed in 2 as the relationship between and is , it is and total participation. So, we can merge A and B into 1 task and to entity C, 1 table is required. Hence, minimum no. of tables required is 2.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Consider the relational schema EMPLOYEE and functional dependencies in the diagram.
(Emp_ID, Course_Title)+ = Emp_ID, Course_Title, Name, Dept_Name, Salary, Date_Completed. So, the Candidate key is (Emp_ID, Course_Title).
Part of the key (Emp_ID) is determining Non-prime attributes, Name, Dept_Name, Salary. So, it is a partial dependency.
Hence, relation EMPLOYEE is in 1NF but not in 2NF.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Consider a schema T(P, Q, R, S) and functional dependencies P -> Q and R -> S. Then the decomposition of T into T1 (P, Q) and T2(R, S) is
dependency preserving and lossless join
lossless join but not dependency preserving
dependency preserving but not lossless join
not dependency preserving and not lossless join
Correct Answer
Option 3
Solution
The schema T(P, Q, R, S) is decomposed into T1 (P, Q) and T2(R, S) and there are only two FDs P -> Q and R -> S. So, the decomposition is dependency preserving
T1 ∩ T2 is empty. So, the decomposition is not lossless.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Which of the following is an example of ordinal data?
Ordinal data has a defined order (e.g., Poor < Fair < Good < Excellent), whereas nominal data like country names or employee IDs do not have a meaningful order.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
You apply z-score normalization to the values [10, 20, 30, 40, 50]. What is the z-score of 40, given that the mean is 30 and the standard deviation is 14.14? [NAT]
0.7
1.2
1.5
2.0
Correct Answer
Option 1
Solution
The z-score formula is: z = (X - µ) / σ = (40 - 30) / 14.14 = 10 / 14.14 ≈ 0.7.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
After applying principal component analysis (PCA) to a dataset with 100 features, the first 5 principal components explain 85% of the variance. What percentage of the original variance is explained by the remaining 95 components?
10%
15%
5%
0%
Correct Answer
Option 2
Solution
If the first 5 components explain 85% of the variance, the remaining 95 components explain 100% - 85% = 15%.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
What is the main advantage of hierarchical clustering?
It doesn't require specifying the number of clusters beforehand.
It is computationally efficient for large datasets.
It is robust to outliers.
It creates compact, spherical clusters.
Correct Answer
Option 1
Solution
The main advantage of hierarchical clustering is that it allows for the determination of the number of clusters after the analysis, as it constructs a dendrogram without requiring a predefined number of clusters.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Finding the shortest path between a pair of nodes in a graph
Finding the shortest path between a pair of nodes in a graph
Predicting if a stock price will rise or fall
Predicting the price of petroleum
Grouping mails as spams or non-spams
Correct Answer
Option 1
Solution
Finding the shortest path between a pair of nodes in a graph
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
For a fully-connected deep network with one hidden layer, increasing the number of hidden units should have what effect on bias and variance?
Decrease bias, increase variance
Increase bias, increase variance
Increase bias, decrease variance
No change
Correct Answer
Option 1
Solution
Increasing the number of hidden units in a fully-connected deep network with one hidden layer allows the model to learn more complex patterns in the training data, which typically reduces bias. However, this increased capacity also makes the model more sensitive to fluctuations in the training data, leading to higher variance and a greater risk of overfitting.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Which of the following are supervised learning problems? [MSQ]
Classifying Spotify users based on their listening history
Weather forecast using data collected by a satellite
Predicting tuberculosis using patient's chest X-Ray
Training a humanoid to walk using a reward system
Correct Answer
Option 1,2,3
Solution
Classifying Spotify users based on their listening history
Weather forecast using data collected by a satellite
Predicting tuberculosis using patient's chest X-Ray
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
For training a binary classification model with three independent variables, you choose to use neural networks. You apply one hidden layer with four neurons. What are the
number of parameters to be estimated? (Consider the bias term as a parameter)
21
Correct Answer
Option 1
Solution
Number of weights from input to hidden layer = 3×4 = 12 Bias term for the four neurons in hidden layer = 4 Number of weights from hidden to output layer = 4 Bias term in the final output layer = 1 Summing the above = 21
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
Which of the following statements are FALSE regarding bias and variance? [MSQ]
Models which overfit have a high bias
Models which overfit have a low bias
Models which underfit have a high variance
Models which underfit have a low variance
Correct Answer
Option 1,3
Solution
Models which overfit have a high bias
Models which underfit have a high variance
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
LDA on a dataset with 100 classes and 1000 features. What is the maximum number of dimensions the data can be reduced to using LDA?
99
Correct Answer
Option 1
Solution
LDA reduces the data to C−1 dimensions, where C is the number of classes.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
Consider using rejection sampling on a Bayesian network. As the number of evidence variables increases, the efficiency of rejection sampling:
Increases linearly.
Decreases linearly
Decreases exponentially.
Remains unchanged
Correct Answer
Option 3
Solution
As the number of evidence variables increases in rejection sampling, the efficiency typically decreases exponentially. This is because the probability of generating a sample that satisfies all the evidence constraints becomes significantly smaller, leading to a dramatic reduction in the number of accepted samples. Consequently, more samples need to be generated to obtain a sufficient number of valid samples, making the process less efficient as the number of evidence variables grows.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
For which type of graphical model is the Variable Elimination algorithm least efficient?
Trees
Polytrees
Loopy networks
Bipartite graphs
Correct Answer
Option 3
Solution
These are networks that contain cycles. In the context of graphical models, loops make inference more complex because variables can influence each other through multiple paths.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
When using the likelihood weighting method for sampling in Bayesian networks, how does the incorporation of more evidence variables generally affect the variance of the weights?
It remains unchanged.
It decreases
It increases.
It becomes zero
Correct Answer
Option 3
Solution
In the likelihood weighting method, when evidence is consistent with a given sample, the weight of that sample is adjusted based on the likelihood of the evidence given the sample. As the number of evidence variables increases, the likelihood of randomly generating a sample that aligns with all the evidence decreases. This means more samples will be assigned low or zero weights. Consequently, the variance among the weights increases.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
The Boolean function [~(~p ∧ q) ∧ ~( ~p ∧ ~q)] ∨ (p ∧ r)] is equal to the Boolean function:
S1: A heuristic is admissible if it never overestimates the cost to reach the goal.
S2: A heuristic is monotonic if it follows the triangle inequality property.
Which one of the following is true referencing the above statements?
Statement S1 is true but statement S2 is false
Statement S1 is false but statement S2 is true
Neither of the statements S1 and S2 are true
Both the statements S1 and S2 are true
Correct Answer
Option 1
Solution
Statement S1: True. A heuristic is considered admissible if it never overestimates the true cost to reach the goal from any given state. This ensures that the heuristic is optimistic and will lead to an optimal solution in algorithms like A*.
Statement S2: False. A heuristic is monotonic (or consistent) if it satisfies the triangle inequality, meaning that the estimated cost from the current node to the goal should not exceed the cost from the current node to a neighboring node plus the estimated cost from the neighboring node to the goal. While monotonicity implies admissibility, it is not accurate to define monotonicity solely based on the triangle inequality without mentioning the relationship to the heuristic values at neighboring nodes.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
The frequency distribution for the value of resistance in ohms of 48 resistors is as shown.
Determine the mean value of resistance.
21.919
20.454
18.236
None of the above
Correct Answer
Option 1
Solution
i.e. the mean value is 21.9 ohms,
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
The probabilities of occurrences of two independent events A and B are 0.5 and 0.8, respectively. What is the probability of occurrence of at least A or B
0.9
0.5
0.2
0.1
Correct Answer
Option 1
Solution
P(A) = 0.5 and P(B) = 0.8
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Consider a binomial random variable X. If X1, X2,..., Xn are independent and identically distributed
samples from the distribution of X with sum ,then the distribution of Y as n→∞ can be approximated as
Exponential
Bernoulli
Binomial
Normal
Correct Answer
Option 4
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Let X be a normal random variable with mean 1 and variance 4. The probability P{X < 0} is
0.5
Greater than zero and less than 0.5
Greater than 0.5 and less than 1.0
1.0
Correct Answer
Option 2
Solution
Given:
‘X’ is a normal random variable with mean 1 and
variance 4 ⇒ X is N(1, 4)
⇒ X = 0 lies the left of the mean X=1,
P(X) for the given variable is as shown below
⇒ P (X < 0) = 0.5 – P (0 < X < 1 )
⇒ 0 < P (X < 0) < 0.5
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Determine the standard deviation from the mean of the set of numbers:
{5, 6, 8, 4, 10,3} correct to 4 significant figures.
2.380
3.256
1.236
4.526
Correct Answer
Option 1
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
A production department has 35 similar milling machines. The number of breakdowns on each machine averages 0.06 per week. Determine the probabilities of having one, and less than three machines breaking down in any week. [MSQ]
probability of 1 breakdown per week is 0.2572
probability of less than 3 breakdowns per week is 0.6497
Both of the above
None of the above
Correct Answer
Option 1,2,3
Solution
The probability of 1 breakdown per week is 0.2572
The probability of less than 3 breakdowns per week is the sum of the probabilities of 0, 1, and 2 breakdowns per week,
i.e. 0.1225 + 0.2572+ 0.2700, i.e. 0.6497
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
A dice is rolled 9 times. Find the probabilities of having a 4 upwards 3 times
0.2534
0.1302
1.235
0.255
Correct Answer
Option 2
Solution
The probability of having a 4 upwards 3 times is 0.1302
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
The standard normal probability function can be approximate as
where = standard normal deviate. If mean and standard deviation of annual precipitation are 102 cm and 27 cm respectively, the probability that the annual precipitation will be between 90 cm and 102 cm is
66.7%
33.3%
50.0%
16.7%
Correct Answer
Option 4
Solution
Given:
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
For a given 2 × 2 matrix A, it is observed that
Then matrix A is
None
Correct Answer
Option 3
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
For what value of a, if any, will the following system of equations in x, y and z have a solution?
Any real number
0
1
There is no such value
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
The eigenvectors of the matrix are written in the form and What is a + b?
0
1/2
1
2
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Let X be a square matrix. Consider the following two
statements on X.
I:X is invertiable.
II: Determinant of X is non-zero.
Which one of the following is TRUE?
I implies II; II does not imply I.
II implies I: I does not imply II
I does not imply II; II does not imply I.
I and II are equivalent statements.
Correct Answer
Option 4
Solution
For the inverse of matrix to exist, the matrix should be
non-singular
(i.e.) determinant is non-zero
∴ I and II are equivalent statements
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Using Cramer’s rule, solve the following set of equations
2x + 3y + z = 9
4x + y = 7
x – 3y – 7z = 6
x = 1;y = 3;z = -2
x = -1;y = -3;z = 2
x = 0;y = 3;z = -1
None of the above
Correct Answer
Option 1
Solution
By Cramer’s Rule
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
For the matrix , one of the normalized eigen vector is given as
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Compute the LU decomposition of
L = U=
Both of the above
None
Correct Answer
Option 1
Solution
Given:
Add -1 times row 1 to row 2 and add -2 times row 1 to row 3
Add row 2 to row 3
In terms of elementary matrices, we have just shown that
Rearrange the equation to get
Combine the matrices as in the proof of the LU decomposition to find
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Let T(x, y, z) = (5x − 3y + z, 2z + 4y, 5x + 3y)
What is the standard matrix of T?
None
Correct Answer
Option 1
Solution
We have T : R3 → R3 . We write vectors x ∈ R3 as columns
Recall the standard basis
We have
So, the standard matrix of T is
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
what’s the limit for f(x) = kx for x∈[a, b].
0
a
b
k
Correct Answer
Option 4
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
The function f(x)=|x+1| on the interval [-2,0]
Continuous and differentiable
Continuous on the integral but not differentiable at all points
Neither continuous nor differentiable
Differentiable but not continuous
Correct Answer
Option 2
Solution
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Find the area contained by y = sin x from x = 0 to x = 3π/2.
3
2
-2
-1
Correct Answer
Option 1
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Points at which f(x) is discontinuous are: [MSQ]
All Positive Integers
All Negative Integers
Zero
None
Correct Answer
Option 1,2,3
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.00
Correct Answer
Option 3
Solution
Hence, C is the correct option.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
0
1
Correct Answer
Option 3
Solution
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Which of the following is the correct way to open a file named “example.txt” in Python for reading?
file = open(“example.txt”, “r”)
file = open(“example.txt”, “read”)
file = open(“example.txt”, “w”)
file = open(“example.txt”, “write”)
Correct Answer
Option 1
Solution
The correct mode for opening a file for reading in Python is “r”
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
What will be the output of the following Python code?
def foo():
try:
return 1
finally:
return 2
k = foo()
print(k)
error, there is more than one return statement in a single try-finally block
3
2
1
Correct Answer
Option 3
Solution
The finally block is executed even though there is a return statement in the try block.
Difficulty Level: 1
Positive Marks: 1.00
Negative Marks: 0.33
Given a Binary Search Tree (BST) and an integer k, return the k-th smallest element in the BST.
def kthSmallest(root, k):
result = []
def inorder(node):
if not node:
return
inorder(node.left)
result.append(node.val)
inorder(node.right)
inorder(root)
return result[k - 1]
def kthSmallest(root, k):
count = 0
def inorder(node):
if node:
inorder(node.left)
count += 1
if count == k:
return node.val
inorder(node.right)
return inorder(root)
def kthSmallest(root, k):
stack = []
while root:
stack.append(root)
root = root.left
while stack:
node = stack.pop()
k -= 1
if k == 0:
return node.val
if node.right:
node = node.right
while node:
stack.append(node)
node = node.left
def kthSmallest(root, k):
stack = []
while root:
stack.append(root)
root = root.right
while stack:
node = stack.pop()
k -= 1
if k == 0:
return node.val
if node.left:
node = node.left
while node:
stack.append(node)
node = node.right
Correct Answer
Option 1
Solution
In this approach, we perform an inorder traversal of the BST, which gives us the elements in sorted order.
The function inorder() traverses the left subtree, then appends the node’s value to the result list, and then traverses the right subtree. Once the traversal is completed, the elements are in increasing order.
The k-th smallest element is simply the (k-1)-th index in the result list (as the list is 0-indexed).
Option B is incorrect because it doesn't handle the return value properly for the k-th smallest element; the count is not updating as intended.
Option C uses a stack and performs an iterative inorder traversal, but it doesn't handle the logic for finding the k-th smallest element correctly.
Option D uses the wrong approach, performing the traversal in the right direction, which doesn't guarantee the elements will be ordered in increasing fashion.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Given a string s and a pattern string p, you need to find all the start indices of p's anagrams in s. An anagram of a string is another string that contains the same characters, only the order of the characters can be different. Write a function find_anagrams that returns a list of starting indices of the anagrams of p in s.
def find_anagrams(s, p):
p_count = [0] * 26
s_count = [0] * 26
result = []
for c in p:
p_count[ord(c) - ord('a')] += 1
for i in range(len(s)):
s_count[ord(s[i]) - ord('a')] += 1
if i >= len(p):
s_count[ord(s[i - len(p)]) - ord('a')] -= 1
if s_count == p_count:
result.append(i - len(p) + 1)
return result
s = "cbaebabacd"
p = "abc"
print(find_anagrams(s, p)) # Output: [0, 6]
s = "abab"
p = "ab"
print(find_anagrams(s, p)) # Output: [0, 1, 2]
s = "afgfhgjk"
p = "fgh"
print(find_anagrams(s, p)) # Output: [1, 2]
s = "abcddcba"
p = "abcd"
print(find_anagrams(s, p)) # Output: [0, 4]
Correct Answer
Option 1
Solution
The find_anagrams function uses two lists p_count and s_count to store the frequency of characters in p and the sliding window of s.
The sliding window moves through the string s, updating s_count to track the frequencies of characters in the current window.
When the window size reaches the size of p, it compares the s_count with p_count. If they are equal, it means that the substring is an anagram of p, and the start index is added to the result.
For Option A, the string s = "cbaebabacd" contains anagrams of p = "abc" starting at indices [0, 6], which is the correct output.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Given a list of integers, write a dynamic programming solution to find the longest increasing subsequence (LIS). Return the correct output for the given array.
The longest_increasing_subsequence function uses dynamic programming to find the LIS.
It initializes a DP array where each index represents the length of the longest subsequence ending at that index.
For each pair of indices, if nums[i] > nums[j], it updates the DP array to reflect the longer subsequence.
The final answer is the maximum value in the DP array. In this case, for the input [10, 9, 2, 5, 3, 7, 101, 18], the LIS is [2, 5, 7, 101], which has a length of 4.
Hence, Option A is correct.
Difficulty Level: 1
Positive Marks: 2.00
Negative Marks: 0.66
Which of the following tasks is NOT a suitable machine learning task?
Finding the shortest path between a pair of nodes in a graph
Predicting if a stock price will rise or fall
Predicting the price of petroleum
Grouping mails as spams or non-spams
Correct Answer
Option 1
Solution
Finding the shortest path between a pair of nodes in a graph








 are written in the form
are written in the form and
and  What is a + b?
What is a + b? , one of the normalized eigen vector is given as
, one of the normalized eigen vector is given as




 U=
U=